
NVIDIA NeMo Framework

Тэхнічныя характарыстыкі
- Назва прадукту: NVIDIA NeMo Framework
- Закранутыя платформы: Windows, Linux, macOS
- Закранутыя версіі: Усе версіі да 24
- Уразлівасць бяспекі: CVE-2025-23360
- Базавы бал ацэнкі рызыкі: 7.1 (CVSS v3.1)
Інструкцыя па ўжыванні прадукту
Усталёўка абнаўлення бяспекі:
Каб абараніць вашу сістэму, выканайце наступныя дзеянні:
- Спампуйце апошнюю версію са старонкі выпускаў NeMo-Framework-Launcher на GitHub.
- Перайдзіце на старонку NVIDIA Product Security для атрымання дадатковай інфармацыі.
Дэталі абнаўлення бяспекі:
Абнаўленне бяспекі ліквідуе ўразлівасць у NVIDIA NeMo Framework, якая можа прывесці да выканання кода і даныхampэрынг.
Абнаўленне праграмнага забеспячэння:
Калі вы выкарыстоўваеце больш ранні выпуск філіяла, рэкамендуецца абнавіць яго да апошняга выпуску філіяла, каб вырашыць праблему бяспекі.
Скончанаview
NVIDIA NeMo Framework - гэта маштабуемая воблачная генератыўная структура штучнага інтэлекту, створаная для даследчыкаў і распрацоўшчыкаў, якія працуюць над Вялікія моўныя мадэлі, Мультымадальны і Гаворка ІІ (напр Аўтаматычнае распазнаванне гаворкі і Тэкст у маўленне). Гэта дазваляе карыстальнікам эфектыўна ствараць, наладжваць і разгортваць новыя генератыўныя мадэлі штучнага інтэлекту, выкарыстоўваючы існуючы код і папярэдне падрыхтаваныя кантрольныя кропкі мадэляў.
Інструкцыя па наладзе: Усталюйце NeMo Framework
NeMo Framework забяспечвае скразную падтрымку для распрацоўкі вялікіх моўных мадэляў (LLM) і мультымадальных мадэляў (MM). Гэта забяспечвае гібкасць выкарыстання лакальна, у цэнтры апрацоўкі дадзеных або з вашым любімым пастаўшчыком воблака. Ён таксама падтрымлівае выкананне ў асяроддзях з падтрымкай SLURM або Kubernetes.

Курыраванне дадзеных
Куратар NeMo [1] гэта бібліятэка Python, якая ўключае ў сябе набор модуляў для здабычы дадзеных і генерацыі сінтэтычных даных. Яны маштабуюцца і аптымізаваны для графічных працэсараў, што робіць іх ідэальнымі для збору дадзеных натуральнай мовы для навучання або тонкай налады LLM. З NeMo Curator вы можаце эфектыўна здабываць высакаякасны тэкст з шырокага сыравіны web крыніцы дадзеных.
Навучанне і налада
NeMo Framework забяспечвае інструменты для эфектыўнага навучання і налады LLM і Мультымадальныя мадэлі. Ён уключае канфігурацыі па змаўчанні для наладкі вылічальнага кластара, загрузкі даных і гіперпараметраў мадэлі, якія можна наладзіць для навучання на новых наборах даных і мадэлях. У дадатак да папярэдняга навучання NeMo падтрымлівае метады кантраляванай дакладнай налады (SFT) і эфектыўнай дакладнай налады параметраў (PEFT), такія як LoRA, Ptuning і іншыя.
Для запуску навучання ў NeMo даступныя два варыянты - з дапамогай інтэрфейсу API NeMo 2.0 або з дапамогай NeMo Run.
- З NeMo Run (рэкамендуецца): NeMo Run забяспечвае інтэрфейс для аптымізацыі канфігурацыі, выканання і кіравання эксперыментамі ў розных вылічальных асяроддзях. Гэта ўключае ў сябе запуск заданняў на вашай працоўнай станцыі лакальна або ў вялікіх кластарах - абодва з уключаным SLURM або Kubernetes у воблачным асяроддзі.
- Папярэдняе навучанне і PEFT Quickstart з NeMo Run
- Выкарыстанне NeMo 2.0 API: Гэты метад добра працуе з простай устаноўкай з выкарыстаннем невялікіх мадэляў, або калі вы зацікаўлены ў напісанні ўласнага карыстальніцкага загрузчыка даных, навучальных цыклаў або змены слаёў мадэлі. Гэта дае вам большую гнуткасць і кантроль над канфігурацыямі, а таксама дазваляе лёгка пашыраць і наладжваць канфігурацыі праграмным шляхам.
-
траining Quickstart з NeMo 2.0 API
-
Пераход з NeMo 1.0 на NeMo 2.0 API
-
Выраўноўванне
- NeMo-Aligner [1] з'яўляецца маштабуемым наборам інструментаў для эфектыўнага выраўноўвання мадэлі. Набор інструментаў мае падтрымку самых сучасных алгарытмаў выраўноўвання мадэляў, такіх як SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF) і многае іншае. Гэтыя алгарытмы дазваляюць карыстальнікам выраўноўваць моўныя мадэлі, каб яны былі больш бяспечнымі, бясшкоднымі і карыснымі.
- Усе кантрольныя кропкі NeMo-Aligner крос-сумяшчальныя з экасістэмай NeMo, што дазваляе далей наладжваць і разгортваць вывад.
Пакрокавы працэс выканання ўсіх трох этапаў RLHF на маленькай мадэлі GPT-2B:
- Навучанне SFT
- Навучанне мадэлі ўзнагароджання
- ПРО навучанне
Акрамя таго, мы дэманструем падтрымку розных іншых новых метадаў выраўноўвання:
- DPO: лёгкі алгарытм выраўноўвання ў параўнанні з RLHF з больш простай функцыяй страт.
- Самастойная гульня Тонкая налада (SPIN)
- SteerLM: метад, заснаваны на кандыцыянаваным SFT, з кіраваным выхадам.
Праверце дакументацыю для атрымання дадатковай інфармацыі: Дакументацыя па выраўноўванню
Мультымадальныя мадэлі
- NeMo Framework забяспечвае аптымізаванае праграмнае забеспячэнне для навучання і разгортвання сучасных мультымадальных мадэляў у некалькіх катэгорыях: мультымадальныя моўныя мадэлі, асновы бачання-моў, мадэлі пераўтварэння тэксту ў відарыс і не толькі 2D-генерацыя з выкарыстаннем палёў нейронавага выпраменьвання (NeRF).
- Кожная катэгорыя прызначана для задавальнення канкрэтных патрэб і дасягненняў у гэтай галіне, выкарыстоўваючы перадавыя мадэлі для апрацоўкі шырокага дыяпазону тыпаў даных, уключаючы тэкст, выявы і 3D-мадэлі.
Заўвага
Мы пераносім падтрымку мультымадальных мадэляў з NeMo 1.0 на NeMo 2.0. Калі вы тым часам хочаце вывучыць гэты дамен, звярніцеся да дакументацыі да выпуску NeMo 24.07 (папярэдні).
Разгортванне і вывад
NeMo Framework забяспечвае розныя шляхі для высновы LLM, якія абслугоўваюць розныя сцэнарыі разгортвання і патрэбы ў прадукцыйнасці.
Разгортванне з дапамогай NVIDIA NIM
- NeMo Framework бесперашкодна інтэгруецца з інструментамі разгортвання мадэлі на ўзроўні прадпрыемства праз NVIDIA NIM. Гэтая інтэграцыя кіруецца NVIDIA TensorRT-LLM, забяспечваючы аптымізаваны і маштабаваны вывад.
- Для атрымання дадатковай інфармацыі аб NIM наведайце NVIDIA webсайт.
Разгортванне з TensorRT-LLM або vLLM
- NeMo Framework прапануе скрыпты і API для экспарту мадэляў у дзве бібліятэкі, аптымізаваныя для вываду, TensorRT-LLM і vLLM, і для разгортвання экспартаванай мадэлі з NVIDIA Triton Inference Server.
- Для сцэнарыяў, якія патрабуюць аптымізаванай прадукцыйнасці, мадэлі NeMo могуць выкарыстоўваць TensorRT-LLM, спецыялізаваную бібліятэку для паскарэння і аптымізацыі высновы LLM на графічных працэсарах NVIDIA. Гэты працэс прадугледжвае пераўтварэнне мадэляў NeMo у фармат, сумяшчальны з TensorRT-LLM, з дапамогай модуля nemo.export.
- Разгортванне LLM скончанаview
- Разгарніце вялікія моўныя мадэлі NeMo з NIM
- Разгарніце вялікія моўныя мадэлі NeMo з TensorRT-LLM
- Разгарніце вялікія моўныя мадэлі NeMo з vLLM
Мадэлі, якія падтрымліваюцца
Вялікія моўныя мадэлі
| Вялікія моўныя мадэлі | Папярэдняя падрыхтоўка і SFT | ПЭФТ | Выраўноўванне | Канвергенцыя навучання FP8 | TRT/TRTLLM | Пераўтварэнне ў і з абдымаючагася твару | Ацэнка |
|---|---|---|---|---|---|---|---|
| Llama3 8B/70B, Llama3.1 405B | так | так | x | Так (часткова праверана) | так | Абодва | так |
| Mixtral 8x7B/8x22B | так | так | x | Так (неправерана) | так | Абодва | так |
| Нематрон 3 8B | так | x | x | Так (неправерана) | x | Абодва | так |
| Нематрон 4 340B | так | x | x | Так (неправерана) | x | Абодва | так |
| Байчуань 2 7B | так | так | x | Так (неправерана) | x | Абодва | так |
| ChatGLM3 6B | так | так | x | Так (неправерана) | x | Абодва | так |
| Джэма 2B/7B | так | так | x | Так (неправерана) | так | Абодва | так |
| Gemma2 2B/9B/27B | так | так | x | Так (неправерана) | x | Абодва | так |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | так | так | x | Так (неправерана) | x | x | так |
| Phi3 міні 4k | x | так | x | Так (неправерана) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | так | так | x | Так (неправерана) | так | Абодва | так |
| StarCoder 15B | так | так | x | Так (неправерана) | так | Абодва | так |
| StarCoder2 3B/7B/15B | так | так | x | Так (неправерана) | так | Абодва | так |
| BERT 110M/340M | так | так | x | Так (неправерана) | x | Абодва | x |
| T5 220M/3B/11B | так | так | x | x | x | x | x |
Мадэлі мовы Vision
| Мадэлі мовы Vision | Папярэдняя падрыхтоўка і SFT | ПЭФТ | Выраўноўванне | Канвергенцыя навучання FP8 | TRT/TRTLLM | Пераўтварэнне ў і з абдымаючагася твару | Ацэнка |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | так | так | x | Так (неправерана) | x | Ад | x |
| Llama 3.2 Vision 11B/90B | так | так | x | Так (неправерана) | x | Ад | x |
| LLaVA Далей (LLaVA 1.6) | так | так | x | Так (неправерана) | x | Ад | x |
Мадэлі ўбудавання
| Убудаванне моўных мадэляў | Папярэдняя падрыхтоўка і SFT | ПЭФТ | Выраўноўванне | Канвергенцыя навучання FP8 | TRT/TRTLLM | Пераўтварэнне ў і з абдымаючагася твару | Ацэнка |
|---|---|---|---|---|---|---|---|
| SBERT 340M | так | x | x | Так (неправерана) | x | Абодва | x |
| Лама 3.2 Убудаванне 1B | так | x | x | Так (неправерана) | x | Абодва | x |
Мадэлі сусветнага фонду
| Мадэлі сусветнага фонду | Пасля трэніроўкі | Паскораны вывад |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | так | так |
| Cosmos-1.0-Diffusion-Text2World-14B | так | так |
| Cosmos-1.0-Diffusion-Video2World-7B | Хутка | Хутка |
| Cosmos-1.0-Diffusion-Video2World-14B | Хутка | Хутка |
| Космас-1.0-Аўтарэгрэсія-4B | так | так |
| Cosmos-1.0-Autoregressive-Video2World-5B | Хутка | Хутка |
| Космас-1.0-Аўтарэгрэсія-12B | так | так |
| Cosmos-1.0-Autoregressive-Video2World-13B | Хутка | Хутка |
Заўвага
NeMo таксама падтрымлівае папярэднюю падрыхтоўку як для дыфузійнай, так і для аўтарэгрэсіўнай архітэктур text2world мадэлі падмурка.
Гаворка ІІ
Распрацоўка размоўных мадэляў штучнага інтэлекту - гэта складаны працэс, які ўключае вызначэнне, пабудову і навучанне мадэляў у пэўных сферах. Для дасягнення высокага ўзроўню дакладнасці гэты працэс звычайна патрабуе некалькіх ітэрацый. Гэта часта ўключае некалькі ітэрацый для дасягнення высокай дакладнасці, тонкай налады розных задач і даменна-спецыфічных даных, забеспячэння прадукцыйнасці навучання і падрыхтоўкі мадэляў для разгортвання вываду.
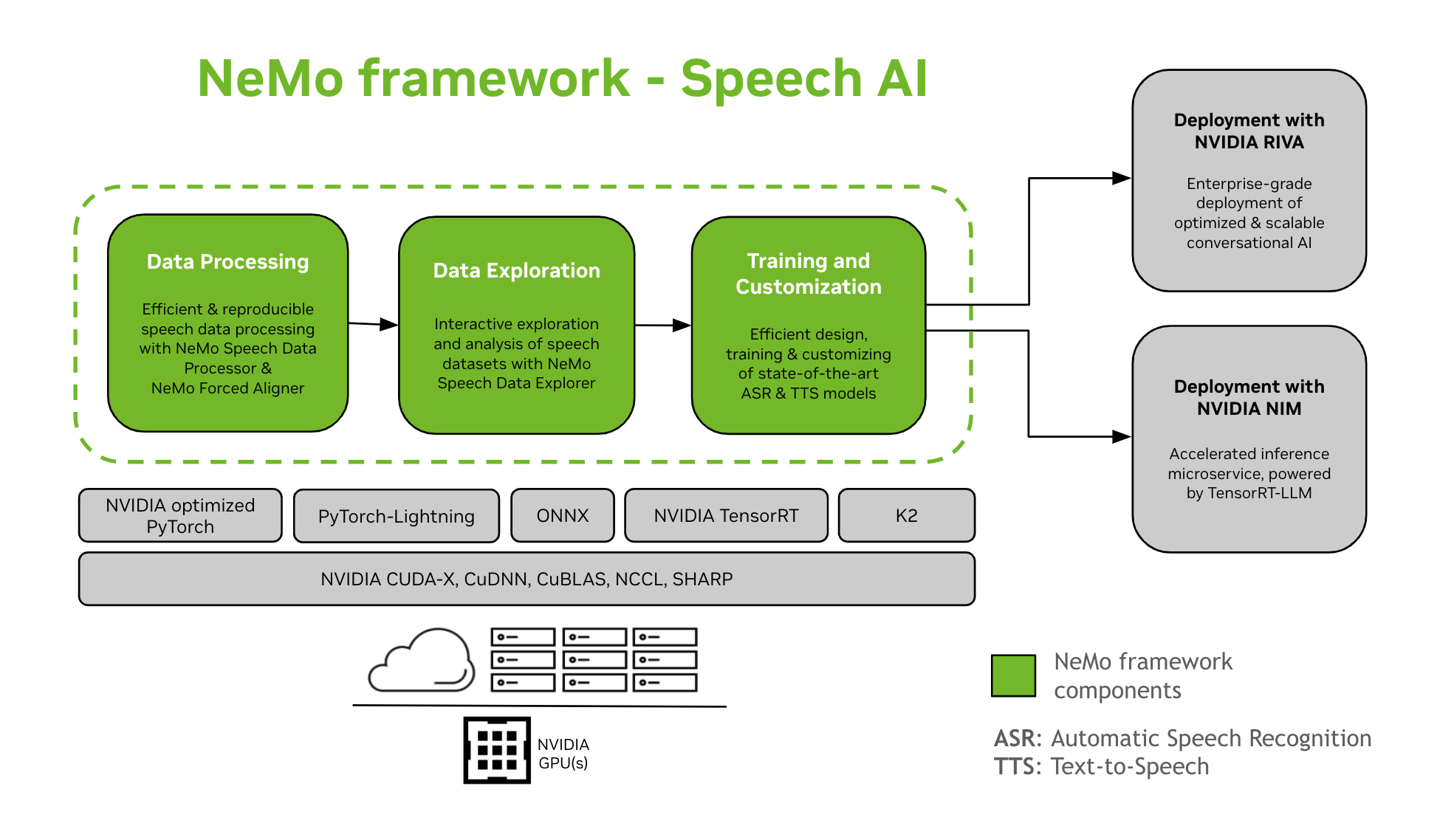
NeMo Framework забяспечвае падтрымку для навучання і налады мадэляў маўленчага штучнага інтэлекту. Гэта ўключае ў сябе такія задачы, як аўтаматычнае распазнаванне маўлення (ASR) і сінтэз тэксту ў маўленне (TTS). Ён прапануе плаўны пераход да разгортвання вытворчасці на карпаратыўным узроўні з NVIDIA Riva. Каб дапамагчы распрацоўшчыкам і даследчыкам, NeMo Framework уключае сучасныя папярэдне падрыхтаваныя кантрольныя кропкі, інструменты для ўзнаўляльнай апрацоўкі маўленчых даных і функцыі для інтэрактыўнага вывучэння і аналізу набораў маўленчых даных. Кампаненты NeMo Framework for Speech AI наступныя:
Навучанне і налада
NeMo Framework змяшчае ўсё неабходнае для навучання і налады маўленчых мадэляў (ASR, Класіфікацыя маўлення, Распазнаванне дынаміка, Дыярызацыя дакладчыка, і TTS) узнаўляльным спосабам.
Папярэдне падрыхтаваныя мадэлі SOTA
- NeMo Framework забяспечвае самыя сучасныя рэцэпты і загадзя падрыхтаваныя кантрольныя кропкі некалькіх ASR і TTS мадэлі, а таксама інструкцыі па іх загрузцы.
- Сродкі маўлення
- NeMo Framework забяспечвае набор інструментаў, карысных для распрацоўкі мадэляў ASR і TTS, у тым ліку:
- NeMo Forced Aligner (NFA) для генерацыі часу на ўзроўні токенаў, слоў і сегментаўampмаўлення ў аўдыя з выкарыстаннем мадэляў аўтаматычнага распазнання гаворкі NeMo на аснове CTC.
- Працэсар маўленчых даных (SDP), набор інструментаў для спрашчэння апрацоўкі маўленчых даных. Гэта дазваляе прадстаўляць аперацыі апрацоўкі даных у канфігурацыі file, зводзячы да мінімуму шаблонны код і забяспечваючы магчымасць узнаўлення і абмену.
- Правадыр маўленчых даных (SDE), на аснове Dash web дадатак для інтэрактыўнага вывучэння і аналізу набораў маўленчых даных.
- Інструмент стварэння набору даных які забяспечвае функцыянальнасць для выраўноўвання доўгага аўдыя files з адпаведнымі транскрыптамі і падзяліць іх на больш кароткія фрагменты, прыдатныя для навучання мадэлі аўтаматычнага распазнавання маўлення (ASR).
- Інструмент параўнання для мадэляў ASR для параўнання прагнозаў розных мадэляў ASR на ўзроўні дакладнасці слоў і выказванняў.
- Ацэншчык ASR для ацэнкі прадукцыйнасці мадэляў ASR і іншых функцый, такіх як выяўленне галасавой актыўнасці.
- Інструмент нармалізацыі тэксту для пераўтварэння тэксту з пісьмовай формы ў вусную форму і наадварот (напрыклад, «31» супраць «трыццаць першага»).
- Шлях да разгортвання
- Мадэлі NeMo, якія былі навучаны або настроены з дапамогай NeMo Framework, можна аптымізаваць і разгарнуць з дапамогай NVIDIA Riva. Riva забяспечвае кантэйнеры і дыяграмы Helm, спецыяльна распрацаваныя для аўтаматызацыі этапаў разгортвання кнопкай.
Іншыя рэсурсы
- НеМо: Галоўнае сховішча для NeMo Framework
- НеМо–Бегчы: Інструмент для канфігурацыі, запуску і кіравання эксперыментамі машыннага навучання.
- NeMo-Aligner: Маштабуемы набор інструментаў для эфектыўнага выраўноўвання мадэлі
- NeMo-Куратар: Маштабуемы набор інструментаў папярэдняй апрацоўкі і курыравання даных для магістраў права
Узаемадзейнічайце з супольнасцю NeMo, задавайце пытанні, атрымлівайце падтрымку або паведамляйце пра памылкі.
- Дыскусіі NeMo
- Праблемы NeMo
Мовы праграмавання і фрэймворкі
- Python: Асноўны інтэрфейс для выкарыстання NeMo Framework
- Пытарч: NeMo Framework створаны на базе PyTorch
Ліцэнзіі
- NeMo Github repo ліцэнзаваны па ліцэнзіі Apache 2.0
- NeMo Framework ліцэнзуецца ў адпаведнасці з ПАГАДНЕННЕМ НА ПРАДУКЦЫЮ NVIDIA AI. Выцягваючы і выкарыстоўваючы кантэйнер, вы прымаеце ўмовы гэтай ліцэнзіі.
- Кантэйнер NeMo Framework змяшчае матэрыялы Llama, якія рэгулююцца Ліцэнзійным пагадненнем супольнасці Meta Llama3.
Зноскі
У цяперашні час падтрымка NeMo Curator і NeMo Aligner для мультымадальных мадэляў знаходзіцца ў стадыі распрацоўкі і будзе даступная вельмі хутка.
FAQ
Пытанне: Як я магу праверыць, ці закранута мая сістэма ўразлівасцю?
A: Вы можаце праверыць, ці закранута ваша сістэма, праверыўшы версію ўсталяванай NVIDIA NeMo Framework. Калі версія ніжэй 24, ваша сістэма можа быць уразлівай.
Пытанне: Хто паведаміў аб праблеме бяспекі CVE-2025-23360?
A: Аб праблеме бяспекі паведаміў Or Peles – JFrog Security. NVIDIA прызнае іх уклад.
Пытанне: Як я магу атрымліваць апавяшчэнні аб бяспецы ў будучыні?
A: Наведайце старонку бяспекі прадукту NVIDIA, каб падпісацца на апавяшчэнні аб бяспецы і атрымліваць інфармацыю аб абнаўленнях бяспекі прадукту.
Дакументы / Рэсурсы
 | NeMo Framework |
Спасылкі
- Кіраўніцтва карыстальнікаmanual.tools